Retrieval augmented generation on private financial data
Aug 12, 2025
5 mins read
Generative AI has moved from novelty to necessity across financial services. Yet for banks, broker dealers, and regulated fintechs, deploying large language models (LLMs) against private financial data is a high stakes endeavor. Retrieval augmented generation (RAG) has emerged as the pragmatic pattern: keep the foundation model largely as is, enrich prompts at inference time with relevant, vetted enterprise data, and return grounded answers that align with policy and compliance. Done right, RAG minimizes fine tuning costs, reduces hallucinations, and creates an audit trail over sources. Done wrong, it leaks sensitive data, amplifies bias, or produces nondeterministic outputs that can’t withstand regulatory scrutiny.
This article outlines reference architectures we’ve seen work in production, guardrails that keep the system safe and compliant, and evaluation approaches that move beyond BLEU scores toward bank grade assurance.
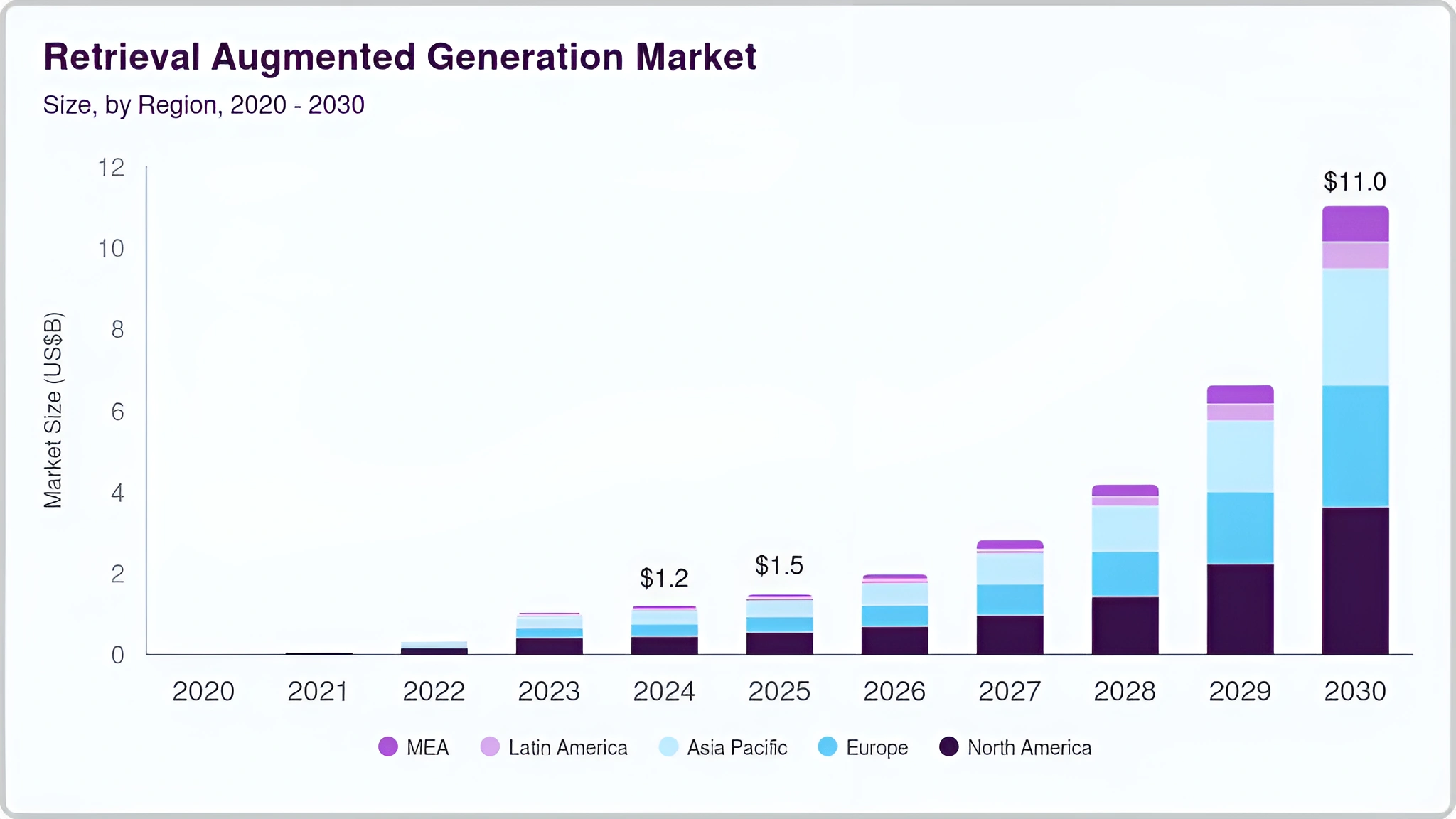
What makes RAG attractive for regulated institutions
RAG decouples knowledge from the model’s weights. Instead of training the model on proprietary documents and customer records, you index them in a secure vector store and dynamically retrieve the most relevant passages per query. Benefits include faster deployment cycles, the ability to revoke or update knowledge instantly, clearer source attribution, and lower exposure to model IP or data exfiltration risks. For organizations subject to privacy regimes (GLBA, GDPR) or supervisory expectations (SR-11-7 for model risk management, OCC-2011-12), these are significant advantages.
A reference architecture that scales and satisfies risk teams
At a high level, a compliant RAG stack for private financial data follows a sequence: identity aware request handling; policy aware retrieval; context assembly with prompt templating; response generation with runtime guardrails; and post response controls including logging, redaction, and human in the loop escalation. The components typically include an API gateway with strong authentication, a policy enforcement service, a feature rich retrieval layer with vector and keyword indexes, a prompt orchestration layer, the LLM runtime (often via a managed provider with private networking), and an observability and governance plane. Each boundary enforces least privilege and separation of concerns, which is crucial for auditability.
Data preparation: the difference between toy demos and production
Document chunking should align with the structure of financial data: prospectuses, research notes, underwriting guidelines, and policy manuals have hierarchical headings and tables. Use structure aware chunking, preserve headers in each chunk, and store metadata such as document IDs, effective dates, regulatory jurisdictions, and confidentiality labels. For customer data, tokenize identifiers and apply deterministic pseudonymization keyed to your data loss prevention policies. Run automated PII detection, but back it with policy based redaction rules that are explainable to auditors. Re index frequently changed sources like product rate sheets on a schedule that matches their operational SLAs.
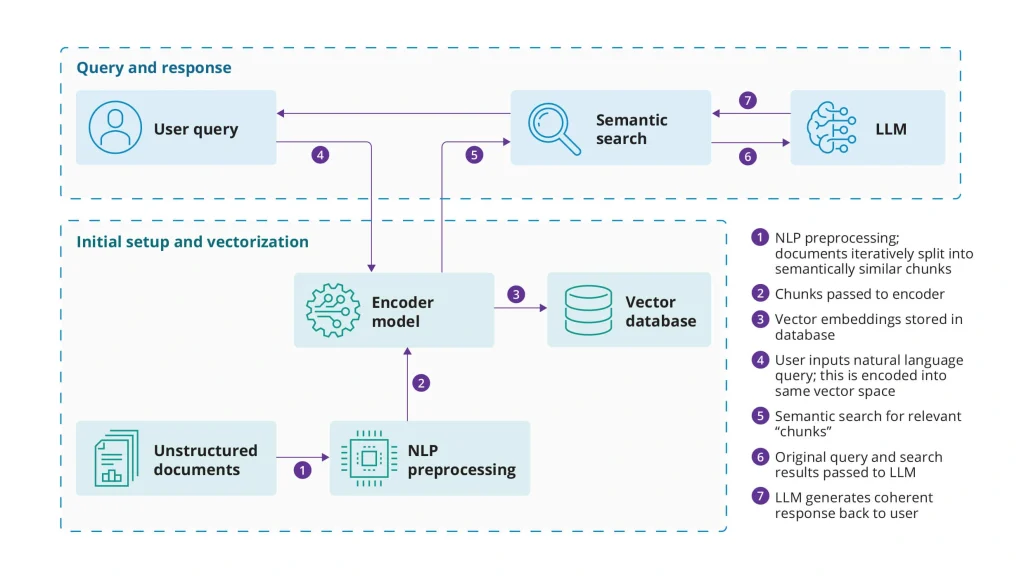
Retrieval for precision and coverage
Combining vector search with sparse retrieval is key. Hybrid retrieval reduces the risk that dense embeddings miss exact term matches like specific covenants or clause numbers. Re rank candidate passages using a cross encoder trained on internal Q/A pairs if allowed; otherwise, use general purpose re rankers to improve precision at top k. Temporal and jurisdictional filters matter: avoid surfacing outdated policy text by prioritizing latest effective date and relevant region. Implement per user ACL filters so retrieval respects entitlements; this must be enforced in the retrieval layer, not just at the UI.
Prompt orchestration with policy context
Standardize prompts with templates that include system instructions for tone, compliance posture, and role. Attach retrieved passages with citations and instruct the model to answer only from those sources. For sensitive use cases (e.g., suitability guidance), force the model to include a “confidence and coverage” note that clarifies scope limits and triggers fallback behavior when retrieval lacks sufficient support. Chain of thought should be disabled or summarized to avoid leaking internal reasoning in customer facing contexts; retain hidden rationales only in logs under restricted access for model risk review.
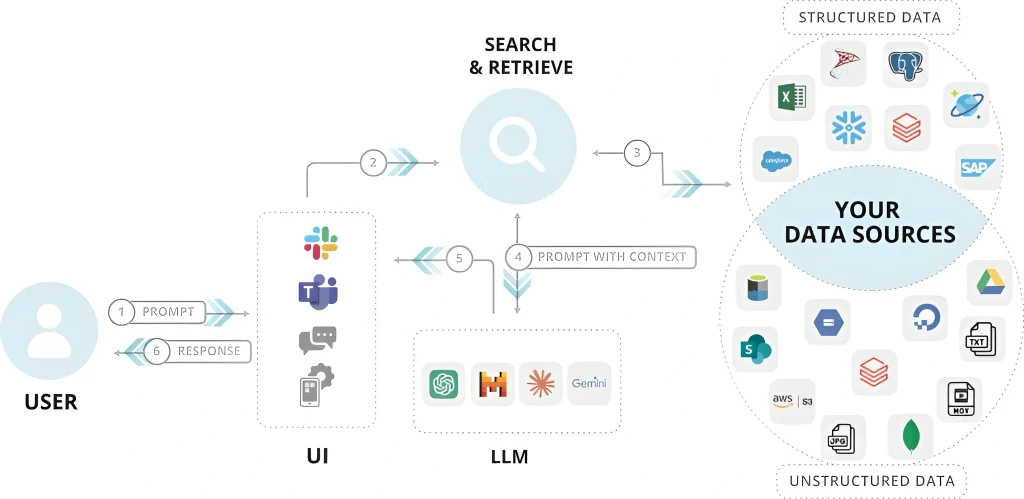
Guardrails: pre , mid , and post generation
Pre generation controls validate inputs: detect PII in the prompt, strip or mask if outside policy, check for prompt injection that attempts to override system instructions, and throttle or reject queries that violate acceptable use. Mid generation controls include a constrained decoding strategy (e.g., temperature caps, top p limits) and content filters for prohibited topics. Post generation controls verify the answer is grounded (citation coverage checks), scan for sensitive data leakage against your DLP dictionaries, and run a policy classifier that can route responses to manual review. Maintain deny allow regex and semantic filters for product claims, forward looking statements, and legal interpretations.
Privacy, security, and data residency
Run inference and vector stores within your VPC or via private connectivity to your model provider. Use encryption at rest and in transit, rotate keys, and tokenize sensitive fields. Apply row and column level security in your data preparation pipeline. For multi region banks, segregate indexes by region to respect data residency constraints; don’t rely on metadata flags alone. Ensure vendor agreements explicitly prohibit model training on your data. Maintain data retention policies for logs; scrub or tokenize PII in prompt/response logs and store decryption keys separately with HSM controls.
Evaluation: from metrics to assurance
Traditional NLP metrics don’t capture RAG’s unique failure modes. Build an evaluation framework around four axes: retrieval quality (hit rate of relevant chunks; coverage of cited sources), faithfulness (does the answer stay within retrieved evidence), safety/compliance (prohibited content and leakage rates), and task utility (does it actually help the user). Create a golden set of queries derived from real workflows: credit policy lookups, fee disclosures, sanctions screening nuances. Human annotators ideally subject matter experts should score faithfulness and usefulness. Automate regression checks so any change to embeddings, re rankers, or prompts runs against the suite. Track hallucination rate as the fraction of claims not supported by citations. For regulated contexts, maintain model documentation per SR 11 7: purpose, data lineage, validation results, limitations, and change logs.
Operating the system: observability and governance
Instrument traces that capture retrieval candidates, final context window, model parameters, and response. Provide replay tooling for investigations. Monitor for drift in retrieval performance and answer quality; alerts should trigger if faithfulness or coverage dips below thresholds. A change management board should approve updates to embeddings, prompt templates, and guardrail rules. Emergency rollback paths are essential. Incorporate human in the loop for high risk categories, with clear SLAs and an escalation matrix.
Use cases that work today
Internal knowledge assistants for frontline teams, document summarization with citations for compliance bulletins, customer service augmentation that pulls from approved knowledge bases, and analyst productivity for research teams are strong early wins. High stakes outputs like credit decisions and suitability recommendations should be positioned as assistive, with clear human review until your evaluation demonstrates sustained reliability and compliance buy in.
RAG can be safe, useful, and defensible in regulated environments but only with an architecture that treats retrieval, guardrails, and evaluation as first class citizens. The institutions that succeed will blend engineering rigor with model risk discipline, delivering AI that is both powerful and prudent.
Maybe you're interested
Real time risk and anomaly detection using streaming feature stores
Fraudsters don’t wait for your nightly ETL. Market microstructure events unfold in milliseconds. Payment networks demand authorization decisions in under 200 ms. Yet many risk programs still run on ba...
Aug 12, 2025
5 mins read
Behavioral biometrics and risk based authentication
Security teams walk a tightrope: reduce fraud and account takeover without piling friction onto legitimate users. Traditional step up controls OTP, SMS, KBA erode conversion and can be phished. Risk b...
Aug 12, 2025
4 mins read
Real time risk and anomaly detection using streaming feature stores
Fraudsters don’t wait for your nightly ETL. Market microstructure events unfold in milliseconds. Payment networks demand authorization decisions in under 200 ms. Yet many risk programs still run on ba...
Aug 12, 2025
5 mins read
Behavioral biometrics and risk based authentication
Security teams walk a tightrope: reduce fraud and account takeover without piling friction onto legitimate users. Traditional step up controls OTP, SMS, KBA erode conversion and can be phished. Risk b...
Aug 12, 2025
4 mins read





